华为 HCIP - AI EI Developer 学习笔记
考试大纲
- 神经网络基础 4%
- 图像处理理论和应用 26%
- 语音处理理论和应用 10%
- 自然语言处理理论和应用 10%
- 华为 AI 发展战略与全栈全场景解决方案介绍 2%
- ModelArts 概览 4%
- 图像处理实验 12%
- 语音处理实验 12%
- 自然语言处理实验 10%
- ModelArts 平台开发实验 10%
神经网络基础
深度学习预备知识
AI、机器学习、深度学习的关系
- AI 四要素: 数据、算法、算力、场景
人工神经网络
深度学习的发展历史
- 1969: Minsky 和 Papert 提出感知机无法解决 XOR 问题
- 1989: George Cybenko 提出万能逼近定理(为什么要这么多非线性隐藏层呢?)
激活函数设计需考虑的因素
- 非线性
- 连续可微性
- 有界性
- 单调性
- 平滑性
图像处理理论和应用
计算机视觉概览
计算机视觉核心问题
计算机视觉核心问题:
- 图像识别: 图像分类、识别
- 图像重建: 从二维图像到三维图像信息,如断层扫描
- 图像重组: 从像素点到目标,如图像像素分割
数字图像处理基础
图像数字化
- 图像数字化包括两种处理过程:采样和量化。
采样
- 图像数字化的采样过程是将空间上连续的图像变化为离散的点。
- 采样后得到离散图像的尺寸称为图像分辨率。分辨率由宽(width)和高(height)两个参数构成。宽表示水平方向的细节数,高表示垂直方向的细节数。
量化
- 数字图像处理的量化过程是将采样点的传感器信号转换成离散的整数值。
- 量化后得到离散图像的每个采样点的变化范围称为灰度级(Gray level scale)。灰度级通常是 2 的整数次幂。我们用 m 级或者 n 位来表示灰度级。图像数据的灰度级越多视觉效果就越好。计算机中最常用的是 8 位图像。
灰度图像的表示
- 像素的数据维度被称为通道(channel)
彩色图像 - HSV
- 该颜色空间可以用一个圆锥来表示。HSV 表示色相(hue)、饱和度(saturation)和亮度(value)。
- H 表示颜色的相位角(hue),取值范围是 0 到 360 度;
- 即圆锥的角度
- S 表示颜色的饱和度(saturation),范围从 0 到 1,它表示成所选颜色的纯度和该颜色最大的纯度之间的比率;
- V 表示色彩的明亮程度(value),范围从 0 到 1。
像素关系
- 对于坐标 的像素 P,P 有四个水平垂直的相邻像素,称为 4-邻域:
,,, - P 有四个对角相邻像素,称为对角邻域:
,,,。 - 4-邻域和对角邻域合称为像素 P 的 8-邻域。
像素的连接
- 如果两个像素不仅空间位置上邻接,并且其像素值也符合相似准则,我们称这两个像素是连接的。
- 像素值的相似准则指像素的灰度值相等,或者像素值都在一个灰度集合 V 中。
- 4-连接:
像素 p,q 都在 V 中取值,且 q 在 p 的 4-邻域中,称它们是 4-连接。 - 8-连接:
像素 p,q 都在 V 中取值,且 q 在 p 的 8-邻域中,称它们是 8-连接。
连通域
- 在一副图像中,一个像素集合内部两两连通,并和集合外部的像素都不连通,这样的像素集合被称为连通域。
- 根据连接的不同定义,连通域同样分为 4-连通域,8-连通域。
- 连通域的边界称为区域的边界或轮廓
图像预处理技术
图像处理的形式
- 对于人工智能方向的图像处理任务,最终的处理结果通常是代表具体内容的数字或者符号。
图像预处理
- 图像预处理的主要目的之一是消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性、最大限度地简化数据,从而改进特征提取、图像分割、匹配和识别的可靠性。
- 图像预处理的流程主要包括:灰度变换,几何矫正,图像增强,图像滤波等操作。
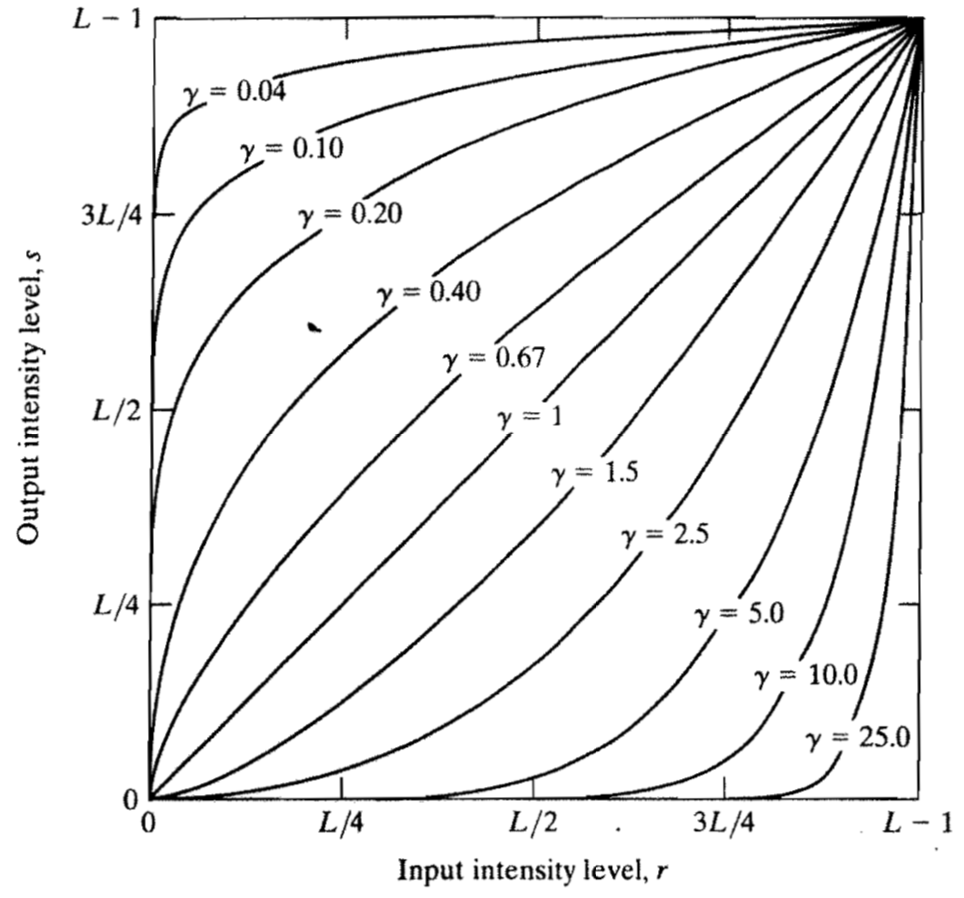
伽马矫正
- 当 γ>1 时,输入的低灰度范围被压缩,高灰度范围被拉伸,实现了强化亮部,压缩暗部的图像增强效果
- 当 γ<1 时,输入的高灰度范围被压缩,低灰度范围被拉伸,实现了强化暗部,压缩亮部的图像增强效果;
均值滤波
- 均值滤波指模板权重都为 1 的滤波器。它将像素的邻域平均值作为输出结果,均值滤波可以起到图像平滑的效果,可以去除噪声,但随着模板尺寸的增加图像会变得更为模糊。经常用于图像模糊化。
高斯滤波
- 为了减少模板尺寸增加对图像的模糊化,可以使用高斯滤波器,高斯滤波的模板根据高斯分布来确定模板系数,接近中心的权重比边缘的大。5*5 的高斯滤波器如下所示:
中值滤波
- 中值滤波属于模板排序运算的滤波器。中值滤波器将邻域内像素排序后的中位数值输出以代替原像素值。它不仅能实现降噪,而且保留了原始图像的锐度,不会修改原始图像的灰度值。
- 中值滤波的使用非常普遍,它对椒盐噪声(salt &pepper noise)的抑制效果很好在抑制随机噪声的同时能有效保护图像边缘信息。但中值滤波是一种非线性变化它可能会破坏像素点的线性关系,不适用于点、线等细节较多的图像或高精度的图像。
图像锐化
- 锐化处理的主要目的是突出图像中的边缘、轮廓线和图像细节。
- 图像锐化法最常用的是梯度法。对于离散图像的梯度,一阶偏导数采用一阶差分近似表示,即
- 类似地,二阶差分:
边缘检测
- 图像边缘是图像的最基本特征,是图像分割所依赖的最重要特征。
- 边缘检测算子主要有
一阶梯度:Prewitt 梯度算子、Sobel 梯度算子。
二阶梯度:Laplacian 梯度算子。
镜像(1)
- 水平镜像变换的变换矩阵为:,w 为图像宽度。
- 垂直镜像变换的变换矩阵为:,h 为图像高度。
怎么理解呢,相当于把 轴的基向量先反向了,然后再加上图像的宽 / 高平移回原象限
旋转(1)
- 旋转变换的变换矩阵为:
插值
- 插值:实际数字图像中的 的值都是整数,但是坐标变换后得到的坐标 不一定是整数。非整数坐标处的像素值需要用周围的整数坐标的像素值来进行计算,这个过程叫做插值。
- 最邻近插值法: 最邻近插值法直接用点 最近的整数坐标处的灰度值作为点 的值。最邻近插值法计算量小,但是精确度不高,并且可能破坏图像中的线性关系。
- 双线性插值法: 双线性插值法使用点 最近邻的四个像素值进行插值计算,假设使用点临近的四个像素点为 , , , ,又令 , ,为了提高插值法的精度,可使用双线性插值法。
图像处理基本任务
数字图像处理的层次
- 图像处理 - 图像分析 - 图像理解
目标检测 / 目标跟踪
- 目标跟踪和目标检测类似,都需要在图像中定位出目标的位置。区别在于目标检测是在静态的单帧图像中定位目标,而目标跟踪是在连续的多图像中定位目标。
图像处理算法的集成应用
四种图像识别的基本任务:
- 图像分类
- 目标检测
- 图像分割
- 目标跟踪
复杂任务应用:
- 文字识别
- 内容检测
特征提取和传统图像处理算法
图像特征提取
- 为了将数字图像有效的转换为结构化数据,需要用到图像特征提取的技术降低数据的维度。其主要思路有:
- 降采样:通过缩放等降采样技术降低待分析图像数据的分辨率。
- 分割感兴趣区域(Region of Interest,RoI):通过分割技术,提取图像中的感兴趣目标的区域,减少待处理的数据量。
- 特征描述子:使用特征描述子将图像转为固定长度的特征向量。
形态学处理
- 图像的形态学处理(morphology)有简化图像数据,增强形状特征,去除干扰噪声等功能。形态学处理的基本操作是膨胀(dilation)和腐蚀(erosion)运算。由基本操作进行组合可实现开运算(opening)、闭运算(closing)等实用的算法。
- 形态学处理在噪声滤除、边界提取、目标定位和区域填充等任务中有着广泛的应用。
膨胀
- 将待处理的图像记为 A,结构元素记为 B,膨胀运算(dilation)是根据 B 的形状,向外扩充 A 中的前景区域。
- 经过膨胀运算后,前景区域的边缘向背景区域膨胀扩增了。
腐蚀
- 将待处理的图像记为 A,结构元素记为 B,腐蚀运算(erosion)就是根据 B 的形状,向内收缩 A 中的前景区域。
- 经过腐蚀运算后,前景区域的边缘被背景区域压缩腐蚀了。
开运算
- 开运算就是用结构元素 B 对图像 A 腐蚀,再用 B 对结果进行膨胀得到最终结果。
- 开运算能够滤除比结构元素小的亮点噪声和突刺,并分离细长的连接。例如将因声影响粘连在一起的区域分割开来。
闭运算
- 闭运算就是用结构元素 B 对图像 A 膨胀,再用 B 对结果进行腐蚀得到最终结果。
- 闭运算可以把填补比结构元素小的暗点缺憾或者空洞,连通细小断裂的区域并平滑边界。例如将因图像质量而断裂的目标区域进行合并连通。
特征描述子
- 图像处理中的特征描述子用于将图像转为固定长度的特征向量。不同的特征描述子被设计出来以描述图像不同属性的特征。图像识别中常用的特征描述子有 HOG 特征 LBP 特征和 Haar 特征等。
图像梯度
- 梯度的方向是函数变化最快的方向。图像中,在物体边缘的梯度值较大,相反,在图像比较平滑的部分,灰度值变化较小,则相应的梯度也较小,图像处理中把梯度的模简称为梯度,由图像梯度构成的图像称为梯度图像。
HOG 算法流程
- HOG 算法流程
- 图像预处理。
- 计算梯度。
- 统计每个 Cell 中的梯度方向加权累计直方图。
- 将几个 Cell 组合成一个 Block,归一化 Block 中每个 Cell 的梯度直方图。
- 将检测窗口中的所有 Block 的 HOG 拼接成一个特征向量,生成特征描述子。
LBP
- 局部二值模式(Local Binary Pattern,LBP)是一种可以描述图像局部纹理特征的描述子。 LBP 具有旋转不变性和灰度不变性等显著的优点。
- 在 3*3 的窗口内,以窗口中心像素为值,将相邻的 8 个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为 1,否则为 0。这样,3*3 邻域内的 8 个点经比较可产生 8 位二进制数,即得到该窗口中心像素点的 LBP 值,这个值反映了该区域的纹理信息。
Haar
- Haar 是一种经典的特征提取描述子。Haar 特征定义了如下图所示的四种基本结构,可以用于提取边缘特征、线性特征、中心特征和对角线特征。

深度学习和卷积神经网络
多卷积核计算

AlexNet 特点
闪光点:
- ReLu:使用 ReLu 代替 Sigmoid 激活函数,以达到快速收敛的目的。
- 重叠的 Pooling:StrideKernel Size。这种池化策略能减轻过拟合。
- 数据增强:为防止过拟合,AlexNet 对进行原始图像(256*256)随机剪裁为 224*224 的图像,图像水平单转以及随机增加光照等操作。
- Dropout:每个隐藏层神经元的输入以 0.5 的概率输出为 0。目的同样是防止过拟合。
VGGNet
- VGG16 相比 AlexNet 的一个改进是采用连续的几个 3x3 的卷积核代替 AlexNet 中的较大卷积核(11x11,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)
- VGGNet 研究深度对卷积网络的影响。使用简单的 3x3 卷积核,不断重复卷积层,池化,最后经过全连接、Softmax,得到输出类别概率。
GoogLeNet & Inception 结构
- GoogLeNet 设计了一种称为 Inception 的模块,它是 GoogleNet 之所以能夺冠的关键。这个模块使用密集结构来近似一个稀疏的 CNN,使用不同大小的卷积核来抓取不同大小的感受。
ResNet & 残差结构
- 残差网络提出了一个可以防止训练时的梯度消失的结构,称为残差结构。
- 残差模块在输入和输出之间建立了一个直接连接,这样新增的网络层仅仅需要在原来的输入层基础上学习新的特征,即学习残差,会比较容易。
SENet & Squeeze-and-Excitation (SE) 模块
- Squeeze 操作: 将一个 channel 上整个空间特征编码为一个全局特征,采用 global average pooling 来实现,最终得到特征图每个 channel 的全局描述特征。
- Excitation 操作: 采用包含两个全连接层的 bottleneck 结构,来提取 channel 之间的关系。
- Scale: Excitation 操作的最后一步是各个 channel 的激活值(sigmoid 激活,值 0~1)乘以 U 上的原始特征。
目标检测与目标分割
目标检测性能度量
目标检测在识别部分的性能度量指标和分类一致,也包括有精度和召回率等。
此外对定位的结果,使用 IoU 参数进行评估,IoU(Intersection over Union)指检测结果和 Ground Truth 的交集和并集的比值。
IoU 值能反映检测结果的准确度,IoU 越接近 1,说明检测结果和真实值越接近。IoU 值大于一定阈值时,才认为正确定位到目标。
目标检测算法评估指标
- 运行速度:
- FPS(Frame Per Second,每秒帧率):表示监测模型能够在指定硬件上每秒处理图片的张数。
- 准确率&召回率:
- mAP(mean Average Precision):综合考虑准确率和召回率的指标。
- mAP 计算思路:对于每张图片,检测模型输出多个预测框(常常远超真实框的个数),我们使用 loU(Intersection Over Union,交并比)来标记预测框是否为预测正确。标记完成后,随着预测框的增多,召回率总会提升,在不同的召回率水平下对准确率做平均,即得到 AP,最后再对所有类别按其所占比例做平均,即得到 mAP。
- 其中 I0U 的阈值通常在(0.5-0.95)中取值。
R-CNN
- R-CNN 网络结构如下所示:
- 基于图片提出若干可能包含物体的候选区域(即图片的局部裁剪,被称为 Region Proposal)。
- 在候选区域上运行当时表现最好的分类网络(AlexNet),得到每个区域内物体的类别。
Fast R-CNN
- R-CNN 耗时的原因是 CNN 是在每一个 Proposal 上单独进行的,没有共享计算,便提出将基础网络在图片整体上运行完毕后,再传入 R-CNN 子网络,共享了大部分计算,故有 Fast 之名。
Faster R-CNN
- Faster R-CNN 提出了 RPN(Regional Proposal Networks)网络取代 Selective Search 算法,使得检测任务可以由神经网络端到端地完成。
- RPN 网络将 Proposal 这一任务建模为二分类(是否为物体)的问题。
- Faster R-CNN = RPN + Fast R-CNN。
YOLO
YOLO 将输入的图片划分成 个单元格,每个单元格负责检测中心点落在该格子内的目标。
每个单元格预测 个边界框(bounding box)和该单元格目标的类别概率。
- 每个边界框使用 5 个值表征:
- 表示边界框的中心坐标
- 表示边界框的宽和高
- 表示该边界框内包含目标且边界框准确的置信度
- 单元格的类别概率使用 个值表征,其中 表示类别个数
- 每个边界框使用 5 个值表征:
每个单元格需要预测的值数量为:。
YOLO 网络最终需要预测的值数量为:。
图像分割的性能度量
通过对比算法分割的区域和 Ground Truth 的区域,可以判断分割结果的优劣。为了直观地表示分割的性能,可以使用 Dice 系数进行评价。
使用 表示 Ground Truth 的面积, 表示分割的结果面积。
表示 Ground Truth 和分割结果重合部分的面积。
语音处理理论与实践
语音处理介绍
语音学
- 语音学大致可以分为四大类型,包含声音从产生到被接受的整个流程的研究
- 发音语音学: 研究言语的声音是怎样通过口腔中的发音器官(比如:唇,牙齿,舌头,声带等)产生出来的。
- 声学语音学: 研究怎样对言语的声音进行声学分析,比如声波的频率,时长,振幅等。
- 听觉语音学: 研究人耳如何接受声音,即人耳对语音的听觉感知。
- 语言语音学: 结合声音,社会环境,个人习惯,语言规律研究声音。
语音信号预处理步骤
语音信号预处理一般包括
- 数字化: 将从传感器采集的模拟语音信号离散化为数字信号;
- 预加重: 预加重的目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率;
- 端点检测: 从语音信号中识别并消除长时间静音段,减少环境对信号的干扰;
- 分帧: 因为语音的短时平稳性,所以要进行“短时分析”,即将信号分段,每一段称为一帧(一般 10-30ms);
- 加窗: 语音信号的分帧是采用可移动的有限长度窗口进行加权的方法来实现的。加窗的目的是减少语音帧的截断效应。常见的窗有:矩形窗、汉宁窗和汉明窗等。
语音信号预处理 - 预加重
- 口唇辐射: 口唇辐射会引起能量损耗,在高频段比较明显,在低频段影响较小。因此为了从消除这影响我们采用一个高通滤波器对信号进行预加重,来加强高频部分分辨率。
语音信号预处理 - 分帧
- 分帧: 将不定长的音频切分成固定长度的小段。
- 分帧虽然可以采用连续分段的方法,但一般要采用交叠分段的方法,这是为了使帧与帧之间平滑过渡,保持其连续性。前一帧和后一帧的交叠部分称为帧移。
语音信号预处理 - 加窗
- 加窗: 分帧后,每一帧的开始和结束都会出现间断。因此分割的帧越多,与原始信号的误差就越大,加窗就是为了解决这个问题,使成帧后的信号变得连续,并且每一都会表现出周期函数的特性。
- 不同的窗函数会影响到语音信号分析的结果。矩形窗平滑性较好,但波形细节丢失,并且会产生泄露现象,而汉明窗可以有效缓解泄露现象,应用范围最为广泛。
语音信号的时域分析
- 语音信号的时域参数:
- 短时能量;
- 短时过零率;
- 短时自相关函数;
- 短时平均幅度差函数;
语音信号的频域分析
- 最常用的频域分析方法为傅里叶分析法。语音信号是一个非平稳过程,因此需要用短时傅里叶变换对语音信号进行频谱分析。通过语音信号的频谱可以观察它们的共振峰特性、基音频率和谐波频率。
语音特征
- 在语音识别和语者识别方面最常用的语音特征就是梅尔倒谱系数(Mel-Frequency Cepstral Coefficients,简称 MFCC)。
- MFCC 提取过程:
- 预加重
- 分帧
- 加窗
- 快速傅里叶变换
- 通过三角带通滤波器得到 Mel 频谱
- 倒谱分析(取对数,做逆变换)
语音识别
传统语音识别任务处理流程
语音文件 → 非压缩语音文件 → 预处理(静音切除,降噪,平滑,标准化)→ 分帧 → 声学特征提取 → 声学模型 → 语言模型 → 单词 → 文本文件
语音识别算法
- 传统语音识别算法:GMM-HMM。
- 基于深度学习的语音识别算法大致可以分为两个方向:
- 混合模型,也成为 hybrid 模型
- 端到端模型,也称为 end2end 模型
语音合成
语音合成处理流程
文本文件 → 文本分析(文本归一化,语音分析,韵律分析)→ 语音内部表示 → 波形合成(毗连合成,共振峰合成,发音合成)→ 波形文件 → 评估
文本分析
- 文本归一化: 对形形色色的自然文本数据进行预处理或者归一化,包括句子的词例还原,非标准词,同形异义词排歧等;
- 语音分析: 文本归一化之后的下一步就是语音分析,具体方法包括通过大规模发音词典,字位-音位转换规则;
- 韵律分析: 分析文本中的平仄格式和押韵规则,这里主要包含三方面的内容,包括:韵律的机构,韵律的突显度,音调。
语音合成方法
- 参数合成
- 并联共振峰合成器
- 串/并联共振峰合成器
- 波形拼接
- 基音同步叠加(PSOLA)方法
语音合成算法
- 基于 HMM 的参数合成
- WaveNet
- Tacotron
- Deep Voice 3
传统声学模型 GMM-HMM
高斯混合模型定义
- 高斯混合模型,英文名:Gaussian Mixture Model(缩写 GMM)。高斯混合模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,它是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。
最大似然法介绍
- 最大似然法 (Maximum Likelihood,ML)也叫极大似然估计,是一种具有理论性的点估计法。最大似然估计是一种统计方法,它用来求一个样本集的相关概率密度函数的参数。
- 此方法的基本思想是:当从模型总体随机抽取 n 组样本观测值后,最合理的参数估计量应该使得从模型中抽取该 n 组样本观测值的概率最大,而不是像最小二乘估计法旨在得到使得模型能最好地拟合样本数据的参数估计量。
最大似然估计
假设有 个独立数据点,均服从某种分布 ,我们想找到一组参数 ,使得生成这些数据点的概率最大,这个概率就是:
称为似然函数(Likelihood Function)。通常单个点的概率很小,连乘之后数据会更小,容易造成浮点数下溢,所以一般取其对数,变成:
称为 log-likelihood function。接下来就可以进行求导,然后求得使得上面式子值最大的参数 。我们认为取得这些观察值的可能性是很小的,但是参数 却使得这一切以最大可能性的发生了。
高斯分布模型参数估计
- 对于一个样本数据集,如果我们使用高斯概率分布来拟合这个数据集,那么求解高斯分布模型参数的步骤如下所示:
- 使用高斯概率分布的概率密度函数;
- 根据样本数据和高斯概率分布的函数形式写出似然函数;
- 将似然函数转化为对数似然函数;
- 对数似然函数对参数求导且令方程为零;
- 解方程得到最优的参数值。
高斯混合模型数学定义
高斯混合模型的概率分布:
对于这个模型而言,参数 也就是每个子模型的期望、方差(或协方差)、在混合模型中发生的概率。
参数解释:
- 表示第 个观测数据,; 是混合模型中高斯模型的数量;
- 是观测数据属于第 个子模型的概率,,且 ;
- 是第 个子模型的高斯分布密度函数,。
高斯混合模型参数学习
对于高斯混合模型,Log-Likelihood 函数是:
如何计算高斯混合模型的参数呢?这里我们无法像单高斯模型那样使用最大似然法来求导求得使 likelihood 最大的参数,因为对于每个观测数据点来说,事先并不知道它是属于哪个子分布的(Hidden Variable),因此 log 里面还有求和, 个高斯模型的和不是一个高斯模型,对于每个子模型都有未知的 ,直接求导无法计算。需要通过迭代的方法求解。
EM 算法
- 最大期望算法(Expectation Maximization Algorithm),是一种迭代算法,用于含有隐变量(Hidden variable)的概率参数模型的最大似然估计或极大后验概率估计。
- EM 算法是 Dempster,Laind,Rubin 于 1977 年提出的求极大似然估计参数的一种方法,它可以从非完整数据集中对参数进行 MLE 估计,是一种非常简单实用的学习算法。这种方法可以广泛地应用于处理缺损数据,截尾数据,带有噪声等所谓的不完全数据。
EM 算法步骤
初始化参数:
E 步骤: 依据当前参数,计算每个数据来自于子模型 的可能性:
其中,;
M 步骤: 计算新一轮迭代的模型参数:
其中,
M 步骤: 计算新一轮迭代的模型参数:
(用这一轮更新后的 )
其中,;
迭代: 重复计算 E-step 和 M-step 直至收敛。
整个 EM 算法可以归结为以下几个步骤:
- 初始化参数;
- 求解期望,也就是每个样本点属于每个单高斯模型的概率;
- 最大化过程,根据期望过程得到的结果,更新参数;
- 迭代上述过程直至收敛。
GMM 优缺点
- 优点:
- 拟合能力强
- 对语音特征匹配概率最大化
- 缺点:
- 无法处理序列因素
- 无法处理线性或近似线性数据
马尔科夫链
- 马尔可夫链,是指数学中具有马尔可夫性质的离散事件随机过程。该过程中,在给定当前知识或信息的情况下,过去对于预测将来是无关的,只与当前状态有关。
- 在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做转移,与不同的状态改变相关的概率叫做转移概率。
马尔科夫链原理
原理:
- 马尔可夫链描述了一种状态序列,其每个状态值取决于前面有限个状态。马尔可夫链是具有马尔可夫性质的随机变量的一个数列。这些变量的范围,即它们所有可能取值的集合,被称为 “状态空间”。
性质:
正定性: 状态转移矩阵中的每一个元素被称为状态转移概率,由概率论知识可知,每个状态转移概率皆为正数,公式可表示为:
有限性: 根据概率论知识,状态转移矩阵中的每一行相加皆为 1,用公式可表示为:
可观测马尔科夫模型
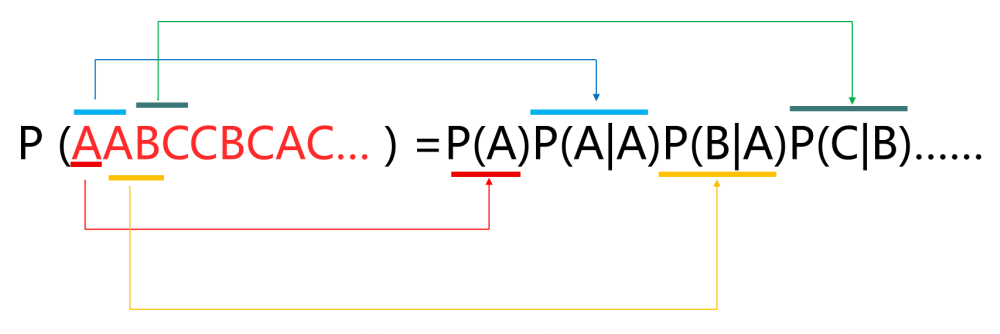
对一个问题而言,我们有初始分布 ,转移概率矩阵 。在给定的任意一个时刻 ,我们都有一个状态 ;一个状态随着时间的变化转移到另一个状态,由此便能得到一个观测序列,即为状态序列 。且整个问题中总共有 个观测状态。
出现这样的序列的概率为:
所以一个可观测的马尔科夫模型由一个三元组 表示,一般情况下可以简写为 。
马尔科夫链学习算法 - 穷举法
穷举法:在马尔科夫模型的学习中,我们采用的是穷举法,也就是概率逼近法。当能拿到的样本序列数据越多,得到的参数的准确性越高。
- 初始概率:
- 转移概率:
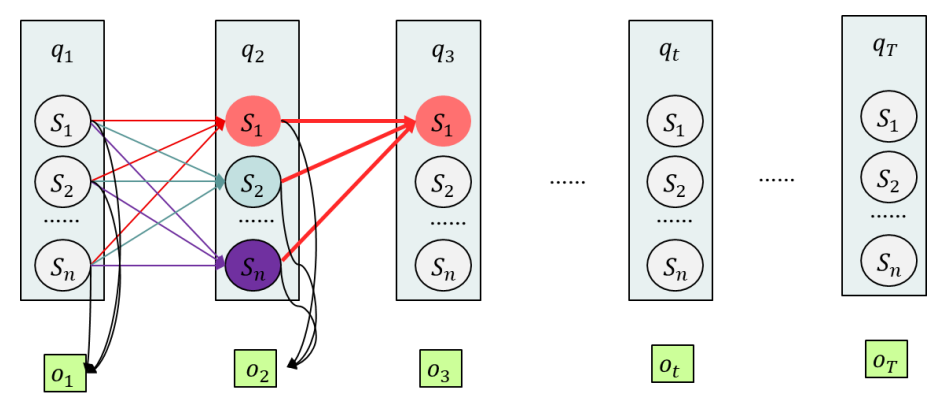
隐马尔科夫模型
HMM 可以用 5 个元素来描述:
- 观测状态集合:; 例如小明的心情状态,开心、不开心、一般。
- 隐藏状态集合:; 例如小明的娱乐活动集合,踢足球、听音乐、看电视。
- 初始概率:; 例如小明的初始心情,这个一般都是作为随机序列起始时的一个假设值,例如小明每个月开始的时候心情状态从 0 开始,不受上个月影响。
- 转移概率:; 例如小明心情之间的转移关系,今天的心情时如何影响明天的心情的。
- 观测概率:; 例如小明的当天的心情和娱乐活动之间的关系,心情是怎样影响娱乐活动的。
根据这 5 个要素,HMM 可以由一个五元组描述 ,也可简写为 。
HMM 三个主要问题
- 评价问题
- 前向算法
- 后向算法
- 解码问题
- 动态规划算法
- Viterbi 算法
- 学习问题
- 监督式算法
- 非监督式 Baum-Welch 算法
隐马尔科夫模型评价问题
- 隐马尔科夫模型评价问题是指:
- 给定了隐马尔科夫模型,包括:
- 初始概率:
- 转移概率:
- 观测概率:
- 隐藏状态集合:
- 可观测状态集合:
- 其中一般默认隐藏状态集合和可观测状态集合在一个问题研究中始终是已知的,很多情况下不会特殊说明它的已知性。
- 给定观测序列;
- 目的是:求解可观测序列出现的概率。
- 给定了隐马尔科夫模型,包括:
隐马尔科夫模型预测算法 - 前向后向算法
前向算法计算过程:
遍历序列点 :
当 时,计算:
当 时,对于每个隐藏状态 ,计算:
得到最终概率 :
算法复杂度:
隐马尔科夫模型学习算法 - 监督算法
- 适用场景:已知大量的可观测的状态序列和对应的隐藏状态序列样本。
- 思想:直接利用大数定理的结论 “频率的极限是概率”,直接给出 HMM 的参数估计。
隐马尔科夫模型学习算法 - Baum-Welch
- 观察序列,没有给出状态序列,求 HMM。
- 其实该算法的本质就是 EM 算法,因为它解决的问题就是:有了观测值,而观测值有个隐变量时,求在 HMM 参数 下的联合概率
- 求解步骤:
- 确定完全数据的对数似然函数
- EM 算法 E 步:求 函数
- EM 算法 M 步:极大化 函数求参数
隐马尔科夫模型解码问题
- 解码问题是指:
- 给定观测序列;
- 目的是:求解产生给定观测序列的最有可能的隐藏状态序列。
隐马尔科夫模型解码算法 - Viterbi
Viterbi 算法的思想比较简单,分为前向计算和后向回溯两个阶段:
前向计算,遍历序列点 :
- 当 时,计算:
- 当 时,对于每个隐藏状态 :
- 记录:
- 计算:
- 记录:
- 当 时,计算:
后向回溯, :
- 遍历序列点 :
- 当 时:
- 当 时:
- 当 时:
- 遍历序列点 :
GMM-HMM 语音识别过程
- 获得语音 wav 文件,以下是一个词识别全过程:
- 将 waveform 切成等长 frames,对每个 frame 提取特征(MFCC)。
- 对每个 frame 的特征跑 GMM,得到每个 frame 属于每个状态的概率 state。
- 根据每个单词的 HMM 状态转移概率 a 计算每个状态 sequence 生成该 frame 的概率: 哪个词的 HMM 序列跑出来 0 概率最大,就判断这段语音属于该词。
GMM 计算: 对于每个 HMM 状态,用一个 GMM 来建模特征空间。GMM 是多个高斯分布的混合,用来表示特征帧在该状态下的概率分布。
隐状态: 这些是模型中不可直接观察的状态。对于语音识别,隐状态通常对应于语音的声学单元(如音素或其子单元)。每个隐状态通过特定的概率分布(如 GMM)来生成观测特征。
GMM-HMM 单字识别
隐马尔科夫模型使用:
- 数字 0 的拼音形式表示了隐藏状态集合;
- 发音序列是隐藏状态序列;
- 音频特征序列是可观测状态序列;
- 隐藏状态之间是有影响关系的,也就是声母韵母之间的转移概率;
- 隐藏状态和观测状态之间有影响关系,也就是声母韵母对观测状态的观测概率。
GMM-HMM 模型的五要素分别是:
观测状态集合:
隐藏状态集合:
声母、韵母、静默音;
初始概率:
数字 0 的合理音频从这三个音节开始的概率;
转移概率:
数字 0 的合理音频中声母、韵母、静默音之间的转移概率;
观测概率:
记 ;数字 0 的三个隐藏状态对应的三个使用 GMM 表示的连续概率分布。
混合模型 DNN-HMM
传统语音识别算法的缺点
- GMM-HMM 主要的缺点有以下三个:
- 由于 GMM-HMM 中,每个隐藏状态都对应了一个 GMM 模型,特别是当进行连续词识别时,状态数量是很大的,因此模型训练会消耗大量的时间且参数空间很大。
- 隐马尔科夫模型对语音识别问题进行建模时,有一个隐藏的条件,就是隐藏状态序列之间需要满足马尔科夫特性,也就是说下一个时刻隐藏状态只和当前时刻的隐藏状态有关系,和过去以及未来的隐藏状态都没有关系,这个假设其实在实际中并不是完全合理的,很多时候是前后多个状态决定中间某个状态的。
- 每个模块是单独进行优化和训练的,模块之间相互耦合关联,这样就导致了不能端到端处理任务,无法根据具体的任务优化整个流程、
深度学习语音识别算法 - Hybrid 模型
- Hybrid 模型是指使用深度神经网络代替传统 GMM-HMM 中的 GMM 模型,可以使用的代替网络有 DNN、CNN、LSTM 以及其他的一些变体神经网络结构。
- 特点:混合模型使用深度神经网络结构代替 GMM 提取语音信号的特征,对其进行深度加工和表征。
- 缺点:无法脱离 HMM,最终还是需要使用 HMM 模型;并且需要使用已经训练好的传统 GMM-HMM 模型进行数据的对齐操作(样本标注),本质上还是需要传统的 GMM-HMM 模型作为起点。整个的网络架构也只是为了训练声学模型,并不是端到端的处理。
CD - DNN - HMM
- 引入了上下文信息(也即前后特征帧信息),由三部分组成:
- 一个 DNN
- 一个 HMM
- 一个状态先验概率分布
高级语音模型
长短时记忆网络
- LSTM 区别于 RNN 的地方,主要就在于它在算法中加入了一个判断信息有用与否的“处理器”,这个处理器作用的结构被称为 cell。一个 cell 当中被放置了三扇门,分别叫做输入门、遗忘门和输出门。一个信息进入 LSTM 的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。

GRU
- 将遗忘门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
- 更新门用于控制前一时刻的状态信息被代入到当前状态的程度,更新门的值越大说明前一时刻的状态信息带入越多。
- 重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。

GRU 特点
- 如果将重置门设置为 1,更新门设置为 0,那么将再次获得标准 RNN 模型。
- 为了解决短期记忆问题,每个递归单元能够自适应捕捉不同尺度的依赖关系。
- 解决梯度消失的问题,在隐层输出的地方 , 的关系用加法(因为是交叉熵 log 求和)而不是 RNN 当中乘法+激活函数。
LSTM 和 GRU 比对
- 标准 LSTM 和 GRU 的差别并不大,都会比普通的 RNN 效果要好。
- GRU 构造相较于 LSTM 更加简单,比 LSTM 少了一个门,所以计算速度会比 LSTM 快。
- LSTM 对于保留的记忆是可控的,而 GRU 不可控。
语音数据对齐
- 如下图所示,在数据对齐时,最简单的解决方案是合并连续重复出现的字母。但是这样 hello 这样的单词背映射成 helo。

- CTC 损失函数是一种 Alignment-free 的算法。在数据对齐时,引入空白字符 表示语音中的停顿。将 通过
映射到 。 操作包括:- 合并连续相同符号;
- 去除空白字符;

CTC 损失函数
- CTC 实现变长的映射。这种对齐方式有以下特征:
- 、 之间的时间片映射是单调的,即如果 向前移动一个时间片, 保持不动或者也向前移动一个时间片;
- 与 之间的映射是多对一的,即多个输出可能对应一个映射,反之则不成立。因此 的长度大于等于 的长度。
RNN+CTC
- 输入的是音频特征序列,输出的是字母序列。
- 输出的字母序列长度和输入的音频特征序列长度是一样的。
- 使用这个模型要处理的一个问题就是,怎样评估模型输出的字母序列和目标字母序列之间的差异。因为音频特征序列的长度是远远比目标字母序列的长度要长的,也就导致网络输出的字母序列比目标字母序列也是长很多,无法对齐。
- 这里使用的 CTC 损失函数评估长度不一致的输出字母序列和目标字母序列之间的差异。
End2End 模型
- End2End 模型是指输入语音特征序列,输出直接是字母或更粗粒度(字)序列的模型。
- 优点: 端到端处理语音识别问题,不需要大量的中间环节。
- 需要解决的问题: 在没有强制输入输出对齐的标注数据的情况下,怎样进行网络训练。目前有两种方法:
- 使用 RNN 系列网络,依赖 CTC(Connectionist Temporal Classification)损失函数评估得到的序列和目标序列之间的差异。
- 使用 Seq2Seq 网络结构进行自动的对齐,使用交叉熵损失函数评估网络预测的序列和目标序列之间的差异。
- 常见的网络模型结构有:
- CNN/RNN/LSTM+CTC
- Seq2Seq+CE、Seq2Seq+Attention+CE
Seq2Seq
- 该模型属于端到端的模型,输入的是音频特征序列,输出的是字母序列。
- 使用 Seq2Seq 模型,对于输入序列和输出序列长度不要求一样,因此输入可以是音频特征序列,输出可以是字母序列或者粒度更大一些的字序列。
- 使用这个模型评估模型输出的字母序列和目标字母序列之间的差异可以直接使用交叉熵损失函数来实现。
Attention 机制
- Seq2seq 模型在处理过长语音时表现不佳,其原因主要在两方面:
- RNN 的长期依赖。(可以用 LSTM 解决)
- Decoder 在解码时,需要考虑所有序列,而这其中夹杂了许多无关的噪声、无关信息,容易出现信息过载的问题。其实大部分输出,只跟输入序列的部分序列有关,而非整个序列。因此基于 Encoder-decoder 模型,加入注意力机制。在输入信息中聚焦于更为关键的信息,降低对其他信息的关注度,甚至过滤掉无关信息,就可以解决信息过载问题,并提高任务处理的效率和准确性。

终于出现 Attention 机制了,Attention is all you need.
Seq2seq 改进模型
- 根据该网络结构的变体也有很多种:
- 通常情况下,加入 Attention 机制会使的模型的效果更好。
- 在叠层的双向 LSTM 中进行 pooling 操作减少 encode 侧的输出序列的长度。
- 对于 encode 和 decode 侧的 RNN 结构可以采用的变体更多,比如 LSTM,双向 LSTM 等。
自然语言处理理论和应用
自然语言处理简介
自然语言理解层次
- 自然语言的理解和分析是一个层次化的过程,具体可分为以下五个层次:
- 语音分析,是要根据音位规则,从语音流中区分出一个个独立的音素,再根据音位形态规则找出音节及其对应的词素或词。
- 词法分析,是找出词汇的各个词素,从中获得语言学的信息。
- 句法分析,是对句子和短语的结构进行分析,目的是要找出词、短语等的相互关系以及各口自在句中的作用。
- 语义分析,是找出词义、结构意义及其结合意义,从而确定语言所表达的真正含义或概念。
- 语用分析,是研究语言所存在的外界环境对语言使用者所产生的影响。
自然语言处理任务和方法
Word2Vec
- 准备一个大的语料库
- 词汇表中的每个词都有对应的向量表示
- 遍历语料库中每篇文章的每个位置,每个位置都有中心词 和对应的一些上下文词
- 用 和 的词向量的内积来计算给定 预测出 (或相反)的概率
- 持续优化调整词向量使得概率最大化
Word2Vec: Skip-gram (SG)
- 用中心词来预测周围的词。在 skipgram 中,会利用周围的词的预测结果情况,使用梯度下降来不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。
Word2Vec: Continuous Bag of Words (CBOW)
- 用周围词预测中心词,利用中心词的预测结果情况,使用梯度下降等方法不断的去调整周围词的向量。当训练完成之后,每个词都会作为中心词把周围词的词向量进行了调整,这样也就获得了整个文本里面所有词的词向量。
Word2Vec: 损失函数
损失函数公式:
- 这个公式用于评估中心词和上下文词之间的概率关系。
概率计算:
- : 当前词的词向量
- : 上下文中词的词向量
点乘评估:
- 点乘评估的是中心词和上下文词的相似性。相似性越高,整体概率越大。
概率归一化:
- 确保输出是一个有效的概率分布。
Word2Vec 问题与改进
- 词汇表中每个词都要算一遍,导致训练太慢
- 优化方法:
- Hierarchical softmax
- Negative sampling
Glove:统计 count 方法与直接预测方法的结合
- 在损失函数中加入共现矩阵
Fasttext:充分利用字符 ngram 信息
- 引入 n-gram 首先是为了解决 word2vec 中的词序问题,比如两个句子“你礼貌吗”和“礼貌你吗”这两个句子仅仅词序不同,但是意思却天差地别,这种情况 word2vec 是检测不到词序的不同的,由此提出了 n-gram。
- 分类模型的 n-gram 是 word 级别的,并非字符级别。
- n-gram 并不是 FastText 模型中必须的,仅仅是锦上添花。
- 和 FastText 都是用求和平均值来预测的。
- 词向量初始化都是随机的,FastText 并没有在 word2vec 预训练词嵌入的基础上再训练。
词向量评估
- 内部评估
- 相似度任务:计算两个词的相似度。比如数据集 wordsim353.
- 类比任务:经典的 King - Queen = Man - Woman。
- 外部评估
- 以实际任务的指标来评价词向量的好坏。如命名实体识别、机器翻译、文本分类等。
文本分类方法
- 传统统计方法
- 特征提取
- 词袋
- TF-IDF
- 特征选择
- 卡方检验
- 信息增益
- 分类器
- 朴素贝叶斯
- SVM
- 特征提取
- 深度学习方法
- TextCNN
- TextRNN
- BERT
特征提取 - 词袋
- 词袋模型 (Bag of Words, Bow)是一种简单的文本向量化的一种方法,它不考虑句子中单词的顺序,只考虑词表(vocabulary)中单词在这个句子中的出现次数。
特征提取 - TF-IDF
TF-IDF(词频-逆文档频率)向量化相比于词袋向量化,更好地考虑了句子中每个词的重要程度。
- : 词 在文档 中的词频
- : 文档总数
- : 包含词 的文档数
特征选择
- 词袋向量化或 TF-IDF 向量化后的特征通常都有高维稀疏的问题,直接给分类器训练通常效果并不好,过高的数据维度也影响训练和预测的速度,因此,通常会使用特征选择的方法过滤一些无效特征。文本分类中常见的特征选择方法有:
- 卡方检验
- 互信息
- 信息增益
卡方检验
- 源于统计学的卡方分布(chi-square),从(类,词项)相关表出发,考虑每一个类和每一个词项的相关情况,度量两者(特征和类别)独立性的缺乏程度,卡方越大,独立性越小,相关性越大。
深度学习方法 - TextCNN
- TextCNN 是一种使用卷积神经网络对文本进行分类的模型。
- 文本在经过词嵌入后被送入神经网络,与 CNN 不同的是,TextCNN 的卷积操作用在一维数据上。
- TextCNN 提取的特征类似 N-gram 模型,是词的局部关系
中文分词
- 中文分词(Chinese Word Segmentation): 指的是将一个汉字序列切分成一个个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。
序列标注方法
- 传统统计方法:
- HMM
- MEMM
- CRF
- 深度学习方法:
- RNN/LSTM
- BiLSTM + CRF
- BERT
HMM
- 隐马尔可夫模型有两个假设:
- 隐状态独立假设(齐次马尔科夫假设):当前状态只与上一状态有关。
- 观测独立假设:当前观测值只由当前隐状态产生,与其他观测值相互独立。
HMM 问题
- 标签偏置
- HMM 的状态独立假设,使得在计算标签转移概率时在局部归一化转移概率,这使得分支少的状态比分支多的状态有着更大的概率,使得算法倾向于选择分支少的状态。
- 上下文特征缺失
- HMM 的观测独立假设,使得算法当前时间步的概率只与当前观测有关,无法利用周围的上下文特征,使得 HMM 的性能非常受限。
CRF
- 条件随机场(Conditional Random Field, CRF),取消了 HMM 的两个独立假设,把标签转移和上下文输入都当做全局特征之一,在全局进行概率归一化,解决了 HMM 的标签偏置和上下文特征缺失问题。
ELMo 词向量
- 在双向模型预训练完成后,模型的编码部分便可以用来计算任意文本的动态词向量表示。在 ELMo 模型中,不同层次的隐含层向量蕴含了不同层次或粒度的文本信息。
- 越接近顶层的 LSTM 隐含层表示,通常编码了更多的语义信息(对于阅读理解类语义信息需求高的任务适用)。
- 接近底层的隐含层表示更偏重于词法句法信息(适用于命名实体识别类任务)
Transformer 模块
自注意力子层(Self-attention Sub-layer): 使用自注意力机制对输入的序列进行新的表示。
前馈神经网络子层(Feedforward Sub-layer): 使用全连接的前馈神经网络对输入向量序列进行进一步变换。
残差连接(Residual Connection, 标记为 “Add”): 对于自注意力子层和前馈神经网络子层,都有一个从输入直接到输出的额外连接,也就是一个跨子层的直连。残差连接可以使深层网络的信息传递更为有效。
层正则化(Layer Normalization): 自注意力子层和前馈神经网络子层进行最终输出之前,会对输出的向量进行层正则化,规范结果向量取值范围,这样易于后面进一步的处理。
自注意力
- 编码器-解码器注意力(Encoder-Decoder Attention)关注的是输入和输出之间的关系,自注意力(Self-Attention)关注的是输入之间的关系。
自然语言处理应用系统
对话系统
| 任务型 (Task) | 聊天 (Chat) | 知识问答 (Knowledge) | 推荐 (Recommendation) | |
|---|---|---|---|---|
| 目的 | 完成任务或动作 | 闲聊 | 知识获取 | 信息推荐 |
| 领域 | 特定域(垂直类) | 开放域 | 开放域 | 特定域 |
| 以话轮数评价 | 越少越好 | 话轮越多越好 | 越少越好 | 越少越好 |
| 应用 | 虚拟个人助理 | 娱乐、情感陪护 | 客服、教育 | 个性化推荐 |
| 典型系统 | Siri、Cortana | 小冰 | IBM Watson | 阿里小蜜 |
任务型对话系统架构

华为 AI 发展战略与全栈全场景解决方案介绍
华为的 AI 解决方案
应用使能: 提供全流程服务(ModelArts),分层 API 和预集成方案。
MindSpore: 支持端、边、云独立的和协同的统一训练和推理框架。
CANN: 芯片算子库和高度自动化算子开发工具。
Ascend: 基于统一、可扩展架构的系列化 AI IP 和芯片。
Atlas: 基于 Ascend 系列 AI 处理器,通过丰富的产品形态,打造面向“端、边、云”的全场景 AI 基础设施方案。
CANN:高性能芯片算子库和自动化算子开发工具
- 芯片算子库和高度自动化算子开发工具: 兼具最优开发效率和算子最佳匹配昇腾芯片性能。
- 融合引擎: 结合昇腾芯片内部存储架构的算子融合,减少算子调用开销和内存搬移,提升性能。
- CCE 算子库: 基于昇腾芯片,深度协同优化的高性能算子库。
- TBE 算子开发工具: 预置丰富 API 接口,支持用户自定义算子开发和自动化调优,丰富算子开发手段和提升开发效率。
- CCE Compiler: 基于 C/C++扩展的异构混合编程语言的编译器及二进制工具集,极致性能、高效编程,实现昇腾芯片全场景支持。
MindSpore:全场景 AI 计算框架
- 全场景统一 API
- 自动微分
- 自动并行
- 自动调优
- MindSpore IR 计算图表达
- On-Device 执行
- Pipeline 并行
- 深度图优化
- 端-边-云按需协作分布式架构(部署、调度、通信等)
处理器:Ascend、GPU、CPU
ModelArts 概览
ModelArts 概览
ModelArts:一站式 AI 开发平台
- 数据处理
- 数据采集
- 数据筛选
- 数据标注
- 版本管理
- 公共数据集
- 特征工程
- 数据评估
- 模型训练
- 在线编码
- PC 端开发环境
- 常用 AI 框架
- 预置算法
- 超参搜索
- 分布式集群
- 模型可视化
- 自动学习
- 多元网络搜索
- 模型管理
- 模型库
- 模型溯源
- 精度跟踪
- 模型评估
- 部署
- 在线服务
- 批量服务
- 边缘服务
- 在线难例挖掘
- AI 市场
- 模型交易
- API 交易
- 数据集交易
- 开发过程共享
- 镜像共享
Gossip
2024 年 11 月 14 日 15:20 留:
我做到了!
花了一周速通 HCIP,居然是小兵。(*下指)
......
那么,代价是什么呢?